The Agentic Data Platform for governed, reliable data
Unify ingestion, lakehouse zones, governance, lineage, and observability—then let autonomous agents keep pipelines healthy and costs controlled.
Deploy in Cloud, VPC, or On-prem. 100 days to value.
Prefer your stack? Bring-Your-Stack delivery →
Proven at enterprise scale
Battle-tested under peak traffic, strict governance, and production SLAs.
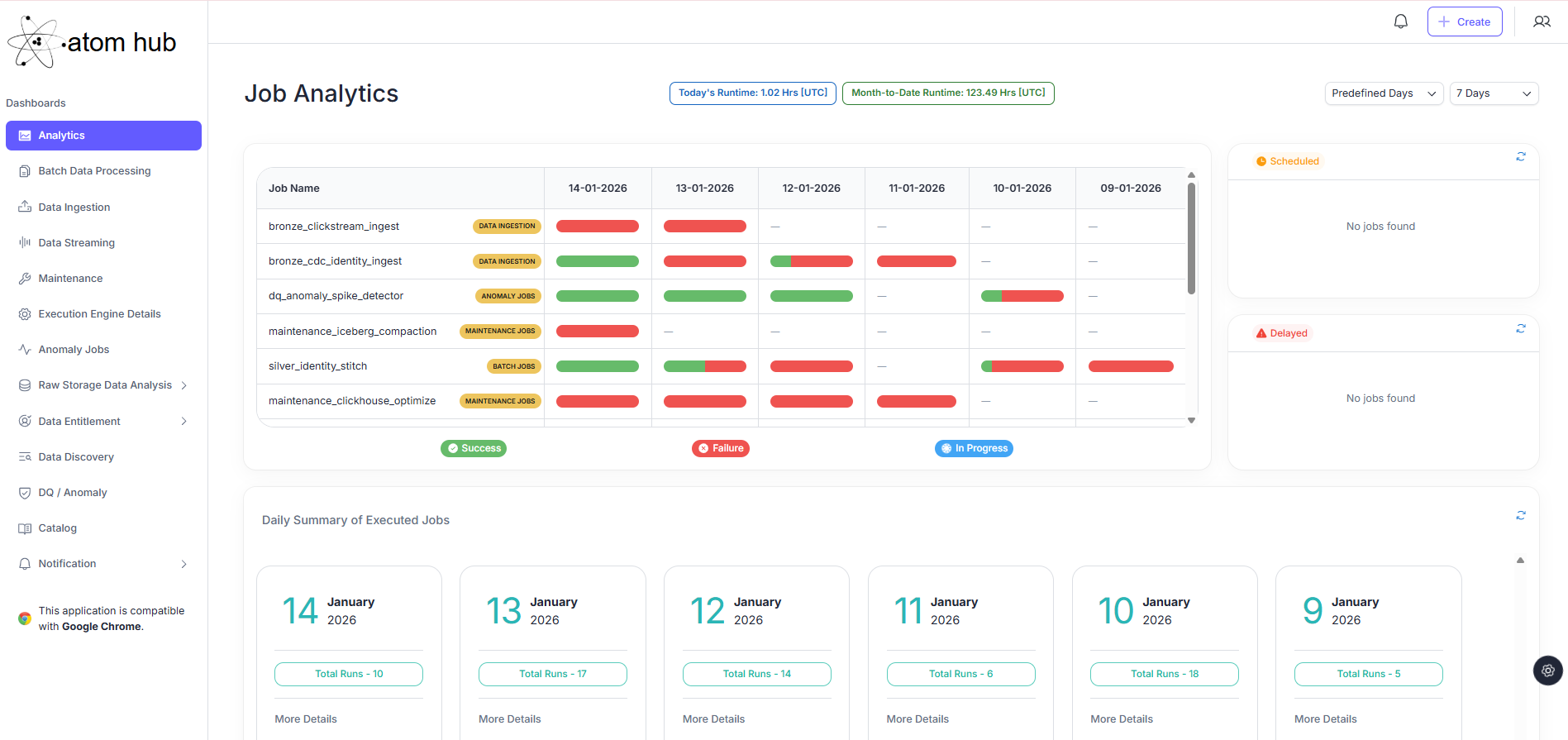
What AtomHub delivers
One platform for the entire data lifecycle—from ingestion to governed insights.
Batch + Streaming + CDC
Unified ingestion for all data sources
Bronze/Silver/Gold Zones
Standardized lakehouse data lifecycle
Data Governance
Quality, security, PII, and entitlements
Catalog + Lineage
Discovery and impact analysis
Monitoring & Alerts
Observability and recoverability
Agentic Operations
Watch, heal, and optimize autonomously
Open standards-first. Works with your stack.
Connect your data
Bring batch, streaming, and CDC into one governed foundation—without rewriting your stack.
- 1Batch ingestion for structured / semi-structured / unstructured sources
- 2Streaming + CDC pipelines for real-time systems
- 3Schema evolution + late arrivals handled safely
- 4Config-driven onboarding with repeatable patterns
Connectors • Sync policies • Schema evolution
Build a lakehouse that stays correct over time
Standardize your data lifecycle with zones, incremental tables, and recoverable pipelines.
- 1Bronze/Silver/Gold zones for raw → refined → curated data
- 2Incremental tables and backfills with lineage-aware impact
- 3Data standards & contracts for consistent modeling
- 4Recoverability: reruns, replays, and safe rollbacks
Zones • Incrementals • Contracts • Recoverability
Governance built into the operating model
Inline/outline quality checks, security controls, and entitlements as first-class platform features.
- 1Inline/outline data quality checks with policy enforcement
- 2Data security: access control and auditability
- 3PII anonymization / masking / pseudonymization-ready
- 4Data entitlements: fine-grained access by role/domain
Quality • Security • PII • Entitlements
Platform services teams actually use
Everything needed to run data operations without stitching 10 tools.
- 1Data Catalog + Data Discovery
- 2Orchestration + Data Processing
- 3Monitoring & Alerts + Data Portal Dashboard
- 4Code repos + CI/CD and standards
Catalog • Orchestration • Discovery • CI/CD
Observability for reliability and cost
Measure freshness, failures, drift, and spend as one operational view.
- 1Pipeline health: failures, latency, freshness SLAs
- 2Data quality health: rule pass/fail trends and anomalies
- 3Usage and entitlement visibility (who used what, when)
- 4Cost & efficiency signals (guardrails, chargeback-ready)
SLOs • DQ • Usage • Cost
Agents that watch, heal, and optimize
Not a chatbot—operational automation that prevents incidents and reduces manual toil.
- Watch: detect SLA risks, drift, and cost spikes proactively
- Heal: automated retries/backfills with safe-guards + approvals
- Optimize: SLA-aware scheduling and right-sizing recommendations
- Explain: quick RCA hints using lineage + runbooks
Recent Agent Actions
Works with your stack
Open standards-first so you can adopt incrementally.











Adopt AtomHub as a control plane—no rip-and-replace required.
Start with a proven pack
Pick one high-impact workflow. Go live fast. Expand.
OTT Clickstream & QoE
- Real-time viewer analytics
- Quality of experience monitoring
- Personalization signals
Payments Reconciliation
- Multi-source reconciliation
- Audit-ready trails
- Exception handling
Lakehouse Migration
- Zero-downtime cutover
- Data validation
- Rollback procedures
Governance & Lineage
- Policy enforcement
- Impact analysis
- Audit preparation
Real-time Monitoring
- Incident reduction
- SLO tracking
- Alert fatigue elimination
Document Intelligence
- Intelligent extraction
- Semantic search
- RAG-ready pipelines
Pricing that avoids platform tax
Simple plans. Transparent metering. One bill—through your cloud.
Freemium
Start free with core capabilities
- Data ingestion
- Data catalog
- Data zones (Bronze/Silver/Gold)
- Data transformation
- Job orchestration
Essentials
For teams launching first production workflows
- AtomHub dashboard
- Basic monitoring & notifications
- Batch jobs
- Metadata management
- Data security
- Processing engine
Advanced
For scale, reliability, and governance
- Real-time/streaming jobs
- Monitoring & alerts
- Recoverability
- Open table formats
- Entitlements & RBAC
- Inline/outline data quality checks
Pro
For enterprise-grade security and self-serve
- Incremental processing (CDC)
- Anomaly detection
- Self-serve capabilities
- Multi-cloud
- PII anonymization
- Compliance-ready controls
- Data mesh enablement
Plans vary by deployment (Cloud, VPC, On-prem) and usage. Contact Sales for a tailored proposal.
Implementation & Customer Success(Optional)
Professional services accelerate onboarding and adoption. AtomHub remains the product.
Launch Pack
30–45 days
First domain live
Migration Pack
60–90 days
Cutover + reconciliation
Reliability Pack
30 days
SLOs + incident reduction
Managed Ops
Ongoing
Run with your team or ours
Frequently asked questions
Everything you need to know about AtomHub deployment, integration, and operations.
Do we need to replace our current stack?
Can AtomHub run on-prem or air-gapped?
How do you handle PII and entitlements?
What does '100 days to value' mean?
How do agents take actions safely?
What standards and integrations are supported?
How does pricing/metering work?
What's the recommended starting workflow?
See AtomHub on your workloads
Bring one dataset and one pain point—we'll show a path to production.